Introduction
In this blog I plan to explain how to use a Scrum sprint with Jira as an ALM tool to manage the sprint and monitor project progress during the sprint to understand the pace of progress and possibly take corrective action. You can use the example explained here for the sprints you plan for your project until all features and deliverables are completed for your project. This blog can give you the cookie cutter process that you can easily adapt to suit your needs, as always one shoe does not fit all but I am hoping the blog will at least assist you with how someone else does things so you can come with a contrast which is better (ha ha). One note for Project managers and Agile geeks who go with pure interpretation of how things are done, I may break some of the written rules in either typical waterfall approach of project management or Agile approach of project management while I am explaining a few things here. My philosophy has always being the following – its mission accomplished, as long as work gets done and the project completed successfully with the golden triangle rule (time, cost, scope and quality) in mind. I much rather have an outcome where the projects are completed successfully than a theoretical conversation on why the process described below is not truly Agile or Waterfall.
Project Summary
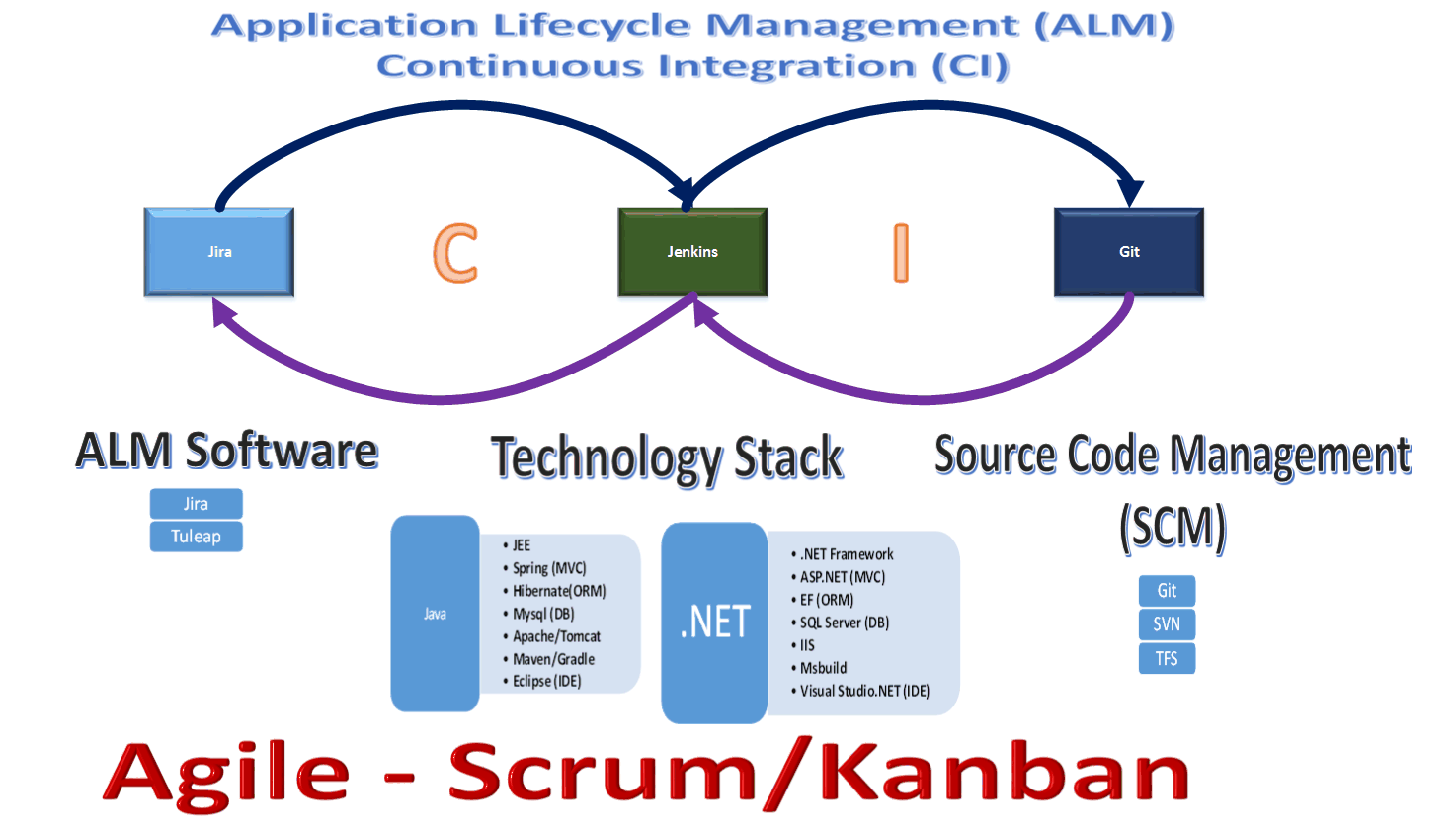
I am planning to use “one” sprint cycle configuration, planning, execution and closure for a fictitious web based application titled – “MyWebApp” (how creative ha-ha) to show how you can use Scrum as an Agile methodology with Jira as a tool for the same. The “Scrum Project Flow” section provides you with the various Scrum terminologies and how they are interrelated.
Scrum Project Flow

Overview of the various elements depicted in the above Diagram

Sample Sprint
We usually start a scrum sprint with backlogs and during sprint planning determine which backlogs we should prioritize and consider for the coming sprint cycle. I have picked two User Stories from my backlogs to do sprint planning. For this example I am not using any “Epic”, as mentioned before “Epic” is just a broader categorization that covers multiple user stories (requirements).
User Stories:
I have two user stories configured for the sprint
User Story1:
We need a web site that allows user registration via an online web portal that can be accessed through Chrome, Firefox and Internet Explorer browsers at a minimum, the web site should support at least N-1 version for each web browser.
User Story2:
Once the user registers via the web portal, we want the internal operations staff to review the registration request and then approve or reject the same using a standard Task screen that is used by them for all tasks that are in their operation queue.
Tasks/Sub-Tasks
For the “User Story1”, I have following Tasks and Sub-Tasks created to track work done to complete the User Story
Task1: Create the user interface in WPF and/or ASP.NET for user registration
- Sub Task1a: Create the User Interface (UI) skeleton with themes and graphics for user registration
- Sub Task1b: Write the data entry validation for user controls both in client side as well as server side for user registration
Task2: Write the ASP.NET MVC controller to do server-side co-ordination between presentation layer and database layer for user registration workflow
- Sub Task2a: Write screen specific server side authentication classes and code business logic in class libraries specific to the registration workflow.
Task3: Write the domain classes representing the ORM layer between the database objects (tables) and the controllers
- Sub Task3a: Create .NET classes in a class library representing the database entities in the database.
Task 4: Write and execute unit test scripts for code validation of user registration screen
NOTE: The above tasks/sub-tasks are just one way in which you can create more specific tasks/sub-task that you can then assign to your Scrum team members to ensure that once they are completed, the user story is completed as well. As always one shoe does not fit all, so go ahead and tweak the above tasks for your specific projects.
During Sprint planning, you will also assign “Story Points” for User Stories and “Original Time Estimate” for User Stories, Tasks and sub-tasks.
Defects/Bugs
By default Jira template for Scrum comes with predefined Issue Types – Epic, User Story, Task, Bug and Sub-Task. Jira also allows you to define your own custom “Issue Types” and “Sub-Tasks”. I prefer to define a custom Sub-Tasks called “Defect” and use that to assign the same as a “Sub-Task” to user stories within a sprint to actively fix defects/bugs while the sprint is active. I do not provide any estimates for this Sub-Task because it’s a defect found while the sprint is active and needs to be fixed before the User Story is said to be “DONE” for the sprint and therefore there is no point in estimating or tracking work efforts for the same. Another benefit of not providing any estimates is that then this sub-task when added to the user story in an active sprint will not be considered as a “Scope” creep change by Jira, which it isn’t.
I use the predefined Issue Type – “Bug” to track real defects/bugs that are identified after the sprint is completed and a code release has occurred. I use “Bug” – Issue Type as priority one backlogs for my next sprint so those defects/bugs get addressed first in the following sprint before any new User Stories are considered for the following sprint execution work load.
Measure & Monitor Work Progress
In this section I am going to explain what Project Manager, Scrum Master and Product Owners can do while the team is working and we are playing “Golf” (he-he) and proactively assisting the team in completing the active sprint on time. Within Jira following are few out of the box reports that can help you with that
- Burndown Chart
- Cumulative Flow Diagram
- Sprint Report
- Velocity Chart
Before I explain the use of each report, a few things that you need to be aware of within Jira. Jira allows you to configure “Estimation” and “Tracking” separately.
Both “Estimation” and “Tracking” can be configured to use “Time”, which is the old school way of doing project management. When I use the term “Time” in this context it means using the typical metrics - “estimated hours, remaining hours, actual hours” to measure work progress.
I like to use “Story Points” for “Estimation” and “Time” for tracking. What I mean by that is within a Sprint I use “Story Points” to track which User Story when complete is going to allow me to collect the “Story Point” assigned to it. This approach of measuring progress is better for “Estimation” than using the typical “estimated hours, remaining hours, actual hours” approach which sometimes can be misinterpreted by the team as micro-management, and I personally feel for Agile methodology is unnecessary as a typical “Sprint” spans for 2-3 weeks and we will know fairly quickly if we are productive (right). I like to start sprints with shorter spans (2 weeks) at the onset of the project since the team needs to get comfortable with each other and the work at hand as well as understand the Agile (Scrum) process. Depending on the first Sprint experience (retrospection), I try to increase the span to 3 weeks after that. So basically if you feel the progress is not at the velocity you expect, then rather than relying on old school way of actively tracking progress using “Time”, I suggest decrease the Sprint time span to take corrective action. It’s possible that the team is being asked to do more than they can handle.
Within Jira, “Time” tracking is disabled for Scrum template by default as Jira is also going with the same philosophical principle explained in the earlier paragraphs by me, adjust Sprint duration to take corrective action. With that said, I tend to use “Time” (estimated hours, remaining hours, actual hours) for tracking active Sprint progress in real time. But, I make it clear to the team that that is truly a way for the team to know what is left on their plate to do and less for me to track their work as I have the “Story Point” approach to do the same. When you set that expectations upfront with the team, then the metrics used for tracking with “Time” becomes easier to fill during Sprint planning(otherwise you end up with the usual hum…, silence…, maybe…, not sure…. type of responses when you ask for estimation hours). Following are the three metrics that you need to be aware of when you enable “Time” for tracking within Jira
- Original Time Estimate
This field is used to do original estimation of work during sprint planning. Again as I mentioned earlier in Agile (Scrum) given that the Sprint duration is short you as a Project Manager/Scrum Master/Product Owner have to focus on the Story Point and not time management with these fields like you do with typical Waterfall type of projects (in Waterfall you tend to do earned-value analysis a lot).
- Remaining Estimate – This is just “Original Time Estimate” minus “Time Spent” and is not filled in by the team but is auto-computed by Jira as long as you are using “Time Spent” to log actual hours.
- Time Spent – This is the field that the team members use to log work hours (actuals) during active sprint and serves the purpose for the team to know what is left on their “TODO” list each day.
The reports that I mentioned earlier will show data differently based on how you configured “Estimation” and “Tracking” setting within Jira. Within this blog unless mentioned otherwise, I am going to go with “Story Points” for “Estimation” and “Time” for tracking which when enabled activates the above three mentioned metrics.
NOTE: Within Jira Issue screen, if the above three fields are not visible then you can make them visible by configuring the User Interface Schema within Jira for Issue screen (within Jira look for pre-defined fields – “Time Tracking” and “Log Work” and add them to the Issue Screen so that the fields are visible on that screen).
In the rest of this section I will provide a brief overview of how each report mentioned earlier can be used along with the metrics to help you track and monitor work progress.
Burndown Chart
This chart helps you understand at what rate are you collecting “Story Points” between Sprints and if required whether you need to adjust your sprint workload for the next sprint to take corrective action. The report is called “Burndown” due to the fact that as you collect Story Points during an active Sprint, the remaining Story Points available for collection decreases until it becomes zero while you are actively collecting them by completing the User Stories.

As shown in the above Burndown chart for my “MyWebApp”, I had one User Story to complete for my Sprint 4 and I did not complete the same within time, the grey line shows when I should have collected the User Story Point and the red line shows the actual. In a perfect world you should try to be as close as you can get to the grey line in terms of you Burndown rate.
Cumulative Flow Diagram
This Report is very useful as it gives a Cumulative flow of various Categories (To Do, In Progress, Done) within the “Issue Types” you are using in Jira. Within Jira (Scrum), the Issue Types that are applicable to use include - Epic, User Story, Task, Sub-Task, and Bug/Defect and the default Categories are - To Do, In Progress, Done.
This report helps you identify potential bottlenecks within the active sprint, as the name (Cumulative flow) suggest, during an active Sprint you should observe the “Done” flow color increasing at the same rate as the “In Progress” flow color decreases which tells you that the team is getting their work done as days progress.
NOTE: You can certainly add your own custom statuses (like QA) and those will add up in this report under one of the three pre-defined non-configurable Jira categories (To Do, In Progress, Done). Jira allows you to add custom Statuses (like QA) but does not allow you to add custom Categories, all statuses need to be clubbed under one of the following three categories - To Do, In Progress, Done. And the cumulative flow diagram shows color coding of the categories not statuses under each of the three categories.

The above screen print provides a sample overview of how my “MyWebApp” projects Cumulative flow looks like. Seems like I am getting a lot of things done (shown by the lack of “Orange”/“Green” and abundance of “Purple” color in the chart especially towards the end of the time period)
Sprint Report
This is the report that helps you actively monitor the progress during a sprint and is one of the reports that you should be actively looking at during the sprint duration. The report shows three color coded lines – “Grey” line is the ideal way in which your project should progress (run) during a sprint. The “Red” line shows you how much of your estimated hours are left to complete (this line is shown if you have enabled “Time” for tracking) and the “Green” shows the actual hours logged if your developers are entering their actual hours (Time Spent) while working during a sprint (again this line is shown if you have enabled “Time” for tracking). You can use this report to tell if your team has over commitment for the active sprint and can take corrective action accordingly.

The above screen print shows the Sprint Report for “Sprint 4” of my “MyWebApp” project. Looking at the report it seems like my team was overcommitted for that Sprint cycle.
Velocity Chart
As the name suggest the Velocity chart shows you the relative velocity of your project from sprint to sprint. Gives you an idea of how well your overall project is progressing. This uses the “Story Points” that you assign to User Stories to show you the relative velocity across Sprints. You only collect Story Points for completed User Stories

The above screen print shows the Velocity Report for my “MyWebApp” project. It seems like I am collecting all Story points from sprint to sprint so my project health looks all right (not sure if my team is getting burned with over commitment but this report makes me feel good until I look at the “Sprint” Report, man the team is over committed, need to do something about it).
Note: For the first two sprints in the Velocity chart you do not see the “Grey” bar because I started those sprints before I gave Story Point estimates for Use Stories and Jira does not like that and hence does not show me the relative estimated Story Point “Grey” bar for the first two sprints.
Hybrid Approach

Hybrid approach of project management is what I recommend you use for large scale projects where you have external facing customers where typically scope changes are wrapped around legal firewalls. As shown in the diagram, you can use Waterfall model as an umbrella framework for external customers and follow all the PMI-PMBOK recommended processes and Knowledge Areas to provide deliverables and continue to use Agile methodology with your internal team for Software/Product development (Feature driven methodology).
Conclusion
I hope this blog will help you plan, execute and monitor your next project better and help you to use Agile (Scrum) within that project. Hopefully I will get time to write about Earned Value Analysis technique in my next blog.
NOTE: I hope to find time to write about Earned Value Analysis technique in my next blog and how you do that in a typical Waterfall style (PMI-PMBOK) project using Microsoft Project as a software tool for the same.