Introduction
In this article I plan to describe how you can use Team Foundation Server (TFS) or Visual Studio Team Service (VSTS) to be Agile in a large scale project with multiple teams working in parallel. I plan to use Scrum terminology a lot in this article and if you are unfamiliar with Scrum then I suggest you read my article on Scrum at: https://www.linkedin.com/post/edit/project-management-using-jira-agile-scrum-jayesh-nazre . In that article I start with describing the terms used in Scrum and then use Jira’s Scrum template to explain how you can be Agile using a “fictitious web based application” project as an example. In this article I will use SAFe (scaled agile) framework and explain how TFS can be configured to use SAFe framework for a large team project. I am going to assume that you are familiar with Scrum terms for the remainder of this article.I am also not going to spend much time providing an overview of SAFe framework in this article as I believe the following website provides a very useful interactive user interface to understand what SAFe framework is https://www.scaledagileframework.com/
Architectural Overview

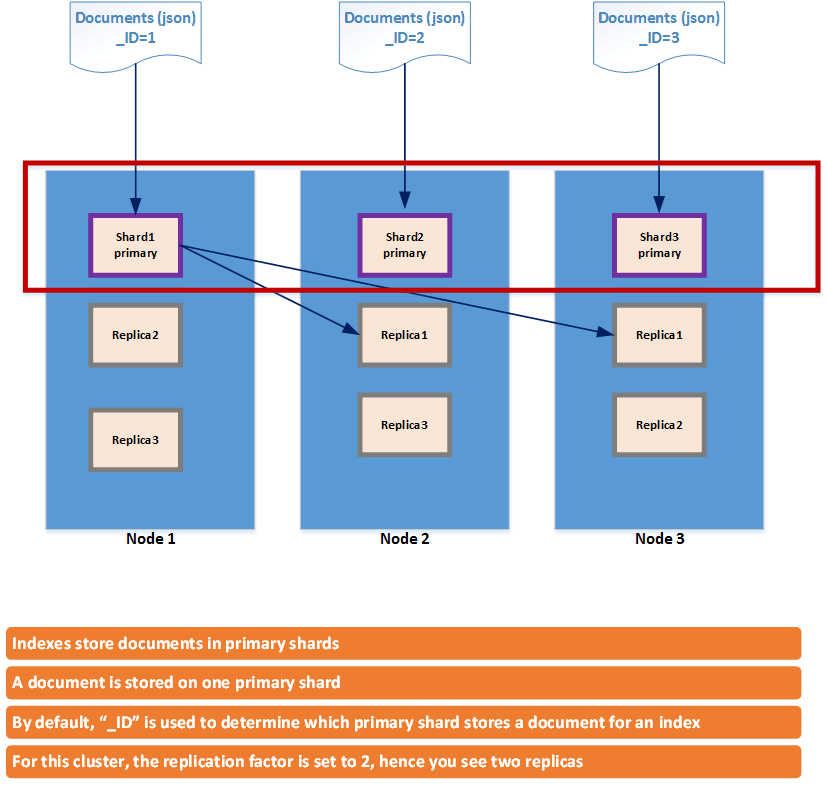
A few observation points about the above diagram
The above diagram is providing a simplified overview of SAFe Framework. The color coding is used by me to help visualize how work gets decomposed from top to bottom. Typically you start with “Epics” in the Portfolio management layer, which is then decomposed into “Features” at the Program management layer which then gets decomposed into “Product Backlog Items (PBI)/User Stories (US)” at the Team level. In TFS/VSTS, there are different templates available when you set up a Team Project. Depending on which template you pick you will get a set of predefined work items. For example in Agile template you get User Stories and in Scrum template you get Product Backlog Items. I am going to use the PBI/US interchangeably within this article. Also unless mentioned otherwise whatever I say for TFS is also applicable for VSTS. Within TFS, the term “Work Item Type (WIT)” is used as a generic term to mean any of the following – Epics, Features, User Stories, Product Backlog item, Tasks, Bugs etc. Depending on which template you select some of the WIT will be available automatically to you within the project. For Example, if you use “Scrum” template following WIT will be made available automatically – Epic, Feature, Product Backlog Item, Task, Impediment and Bug. Instead of Scrum, if you select “Agile” template then following WIT will be made available automatically to you – Epic, Feature, User Story, Task, Issue and Bug.
At the Team level:
In Scrum, you start work by picking work items from the “Team backlog”, into the next sprint during “Sprint Planning”. A Sprint typically runs for 2 weeks (it can run for 3-4 weeks).
At the Program level:
You start with Program Increments (PI) which typically run for 10 weeks. Each iteration within PI is called a Cadence which typically lines up with a single Sprint duration of 2 weeks. The First Cadence is when you do PI planning and the last Cadence is when you do Innovation and Planning. As you can see in the diagram, the framework at the program level aligns with the framework at the Project team level to provide scaling, For Example:- You do Sprint Planning at the beginning and you do PI Planning at the beginning of PI
- You do Sprint Retrospection at the end of the Sprint and you do Innovation and Planning at the end of PI.
At the Portfolio level:
This is where strategy and investment funding are defined for value streams and their Solutions. The portfolio level aligns enterprise strategy to portfolio execution by organizing the lean agile enterprise around the flow of value through one or more value streams. TFS has limited capability to address all aspects of Enterprise Agile Management and Value Stream Management. VersionOne (now Collabnet) is a better software to provide you with the SAFe framework experience than TFS at this level. Within TFS, at this level you have the capability of using Kanban Board just like you do at other levels to define, prioritize, execute and monitor work progress (The Kanban board uses Epics at Portfolio level, Features at Program Level and PBI/US at Team level as show in the diagram). TFS also allows you to use “tags” as a quick and easy way to map Epics to their Value Streams, strategic themes, and associated budgets. But the capability TFS provides is by no means close to what Versionone provides.Some of the things that I have not shown in the above diagram and is worth mentioning is that Continuous Integration/Continuous Deployment (or Delivery) (CI/CD) and Release Management is also something that needs to occur at the Program/Team level and automating that is what provides agility. TFS provides CI/CD and Release Management capability. TFS allows source code versioning through Team Foundation Version Control (TFVC) or Git. Within SAFe Framework, Agile Release Train (ART) is a team of individuals whose goal is to work towards Feature release automation at the program level. Similar automation is also done at the Project Team level but is restricted to Sprint release automation. Typically System demos are events that are organized throughout the PI duration where multiple teams demo what Features are “release ready” and allow teams to collaborate and receive feedback from sponsors, stakeholders, and customers. A similar demo event is done at the Project Team Level at the end of each Sprint.
TFS/VSTS configuration

A few observation points about the above diagram
The above backlog view is visible to all Portfolio level users and is providing a drill down visibility to Portfolio users.
Points 1 through 4:
These points provide a drilldown detail view of which Epics are associated with Features which in turn are associated with PBI which in turn are associated with Tasks providing a top down visibility. It’s possible to control what is accessible to users at what level depending on which TFS groups the TFS teams are assigned to. Within TFS access security controls are enforced through TFS groups, TFS teams and associating users to TFS teams.
Point 5:
Within TFS, Area paths is how you control which TFS team can add which WIT and which TFS teams/TFS groups have access to each Area Path to do the same. This is how TFS allows you to create the top-down hierarchy (Epic to Feature to PBI to Task).
In order to do “PI” at the program level and Sprints at the Team level within TFS you configure the iterations for the project as shown below


TFS/VSTS Build and Release Management

A few observation points about the above diagram
TFS provides complete end to end visibility where in you can associate WIT (like Epics, Features, PBI/US, Bugs) to code checked into the TFVC/GIt at the time of checking in the code. You can also trigger automatic build process based on code check-in event (For example checking in code in “Release” branch in Git). You can also use Gated check-in build with TFVC “only” where in successful build of code before checking it in is mandated. The above diagram shows how Agile Release Train (ART) can be realized through CI/CD pipelines to deliver Features to the customers in continuous manner there by providing value. It’s possible during Release management for an approval workflow to be enabled so releases into production environments can be controlled via a human interaction (an approver). Releases can also be initiated based on triggers like checking in code into a specific Release branch, successful release of code in one environment triggering another environment’s release or doing manual releases. One of the things that I have not shown in the above diagram is that it’s possible to run automatic tests from Test plans as well as run Unit test on application code that’s being built.
A few take away
- SAFe framework and Scrum of Scrums (SoS) are two different things. Scrum of Scrums (also called Meta Scrum) is defined by the Agile Alliance as “A technique to scale Scrum up to large groups”, SAFe, on the other hand, is a complete framework. Put differently, SAFe is prescriptive via its framework, SoS is more of using best practices from Scrum and scaling it to a larger team but is not a very prescriptive approach and assumes that teams are mature enough to scale and be agile.
- Do not try to use SAFe to manage a project with waterfall mind set. That will defeat the purpose of why Agile frameworks exist. The idea is to change the mindset not replace waterfall with another methodology which will end in having the same results as a waterfall model does.
- Although I am showing how to use TFS/VSTS to scale Scrum/Agile projects using SAFe framework. You can also use other software’s like – VersionOne, Jira to do similar scaling. With Jira you can use the BigPicture plug-in to incorporate the SAFe framework within Jira as out of the box Jira does not provide SAFe framework configuration. VersionOne and Jira (with BigPicture) is also a good alternative if you are a non-Microsoft shop.
Conclusion
I hope this helps you understand how to scale Agile/Scrum methodology for large projects using TFS/VSTS and SAFe framework.