Introduction
In this article I plan to provide an overview about the following technologies and a use case where these three can be used to do Data Analytics as well as perform predictive analytics through machine learning.
- Apache Hadoop
- Apache Kafka
- Apache Spark
Architectural Overview
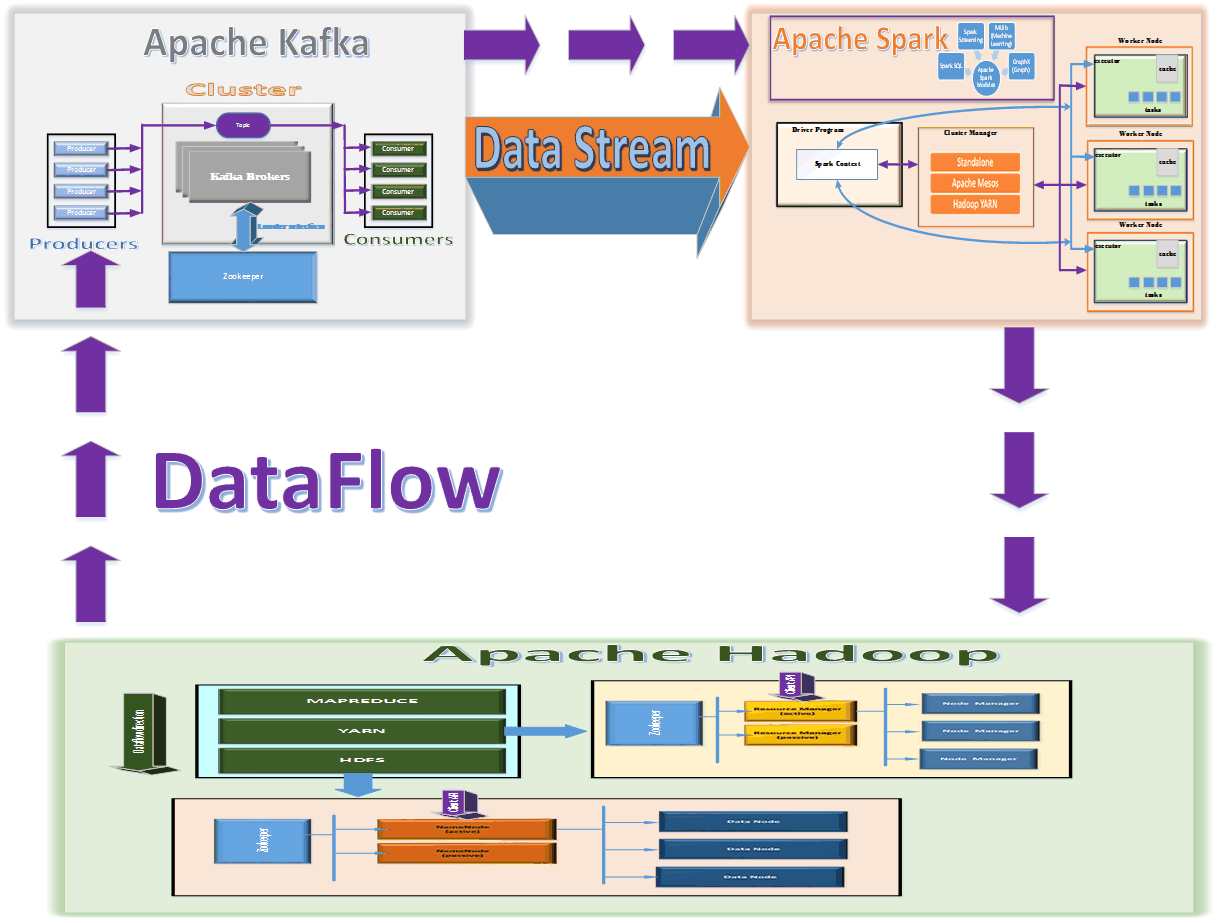
The above diagram provides you with an overview of how the various technologies are working together to allow big data analysis and perform predictive analytics through machine learning.
Apache Kafka
Kafka is used here to provide data streaming (NOTE: For AWS fans you can use Amazon Kinesis for data streaming as well)
Apache Spark
Apache Spark is used to perform data analysis on the data stream (DStream) generated in real time by Apache Kafka. More specifically it’s the Spark Streaming module that’s used. (NOTE: For AWS fans you can deploy an Elastic MapReduce (EMR) cluster in AWS with Spark libraries deployed in that cluster and then use that cluster instead of Apache Spark and Apache Hadoop)
Apache Hadoop
The Hadoop ecosystem serves following purpose here
- It’s used by Kafka consumers to process big data
- It’s used by Spark to store the output results
- It’s used as a Cluster Manager (the YARN piece of Hadoop)
(NOTE: For AWS fans you can deploy an EMR cluster in AWS with Spark libraries deployed in that cluster and then use that cluster instead of Apache Spark and Apache Hadoop)
Apache Hadoop
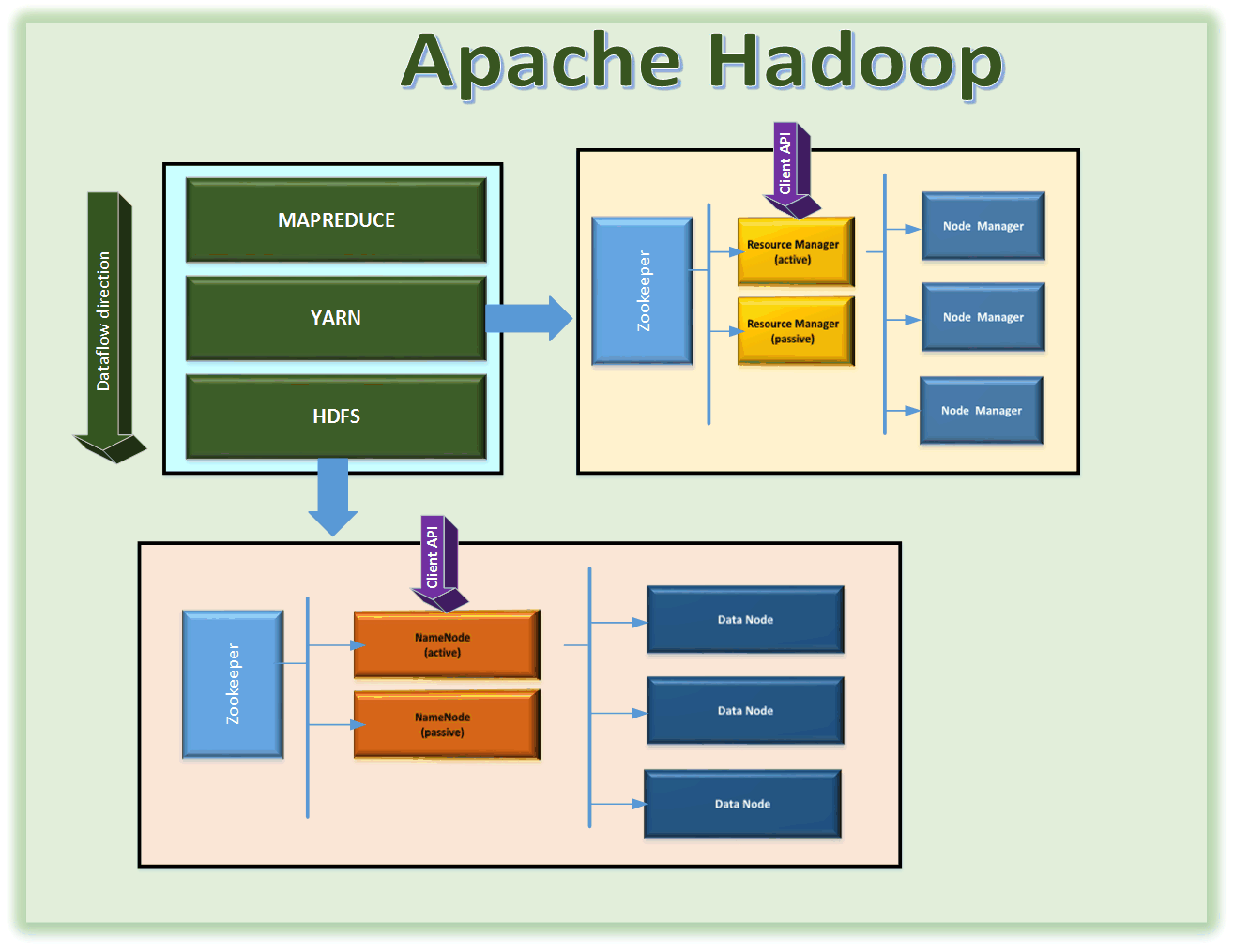
Apache Hadoop is an open source distributed computation platform used for processing big data to perform data analytics (thanks to Google’s published white papers). The Architectural diagram above shows the main modules of Apache Hadoop, a brief description follows
- HDFS - Distributed file system to store big data across commodity server infrastructure
- YARN - Resource Manager engine responsible for co-ordination of cluster resources and the acronym “Yet Another Resource Negotiator” (YARN) is pretty self-explanatory
- MAPREDUCE – It’s the de-facto parallel, distributed programming algorithm used on a Hadoop cluster.
(NOTE: I am excluding quite a few modules to simplify the articles intent).
HDFS
As mentioned before HDFS is the Hadoop Distributed File System. The critical components of HDFS are
- NameNode
NameNode stores the file/directory system structure of the distributed file system
- DataNode
DatNodes are servers that store the actual big data blocks. Failover capability is built into DataNodes as the datablocks are replicated across multiple DataNodes based on replication factor (NOTE: typically for production you should have a replication factor of 3 or 5)
- ZooKeeper
This is used to manage fail-over of resources, in the above example – the NameNode has an active-passive configuration with the zookeeper acting as the gatekeeper to listen to heart beats and doing fail-over action to passive NameNode if the active NameNode fails. (NOTE: Even though the diagram shows one box for Zookeeper in production Zookeeper daemons typically will be running on multiple nodes to provide High Availability (HA))
YARN
YARN is the Resource manager for Hadoop. Prior to YARN, Apache Hadoop had a different architecture for Resource Management that was not as scalable as YARN and was integrated with the MapReduce programming algorithm, starting with Apache Hadoop 2.X, Hadoop separated the Resource Management responsibility from the MapReduce programming algorithm. By doing this separation Hadoop opened the possibility for other projects to use YARN and HDFS without using the MapReduce programming algorithm.
This allowed other technology platforms like Apache Spark to come into picture to run Spark jobs on Hadoop systems using Hadoops Resource Manager (YARN) as Spark’s Cluster Manager and the underling HDFS file system for big data.
Apache Spark jobs are faster than their MapReduce equivalent and one of the reasons for that is the usage of Directed Acyclic Graphs (DAG)
MAPREDUCE
It’s the de-facto parallel, distributed programming algorithm used on a Hadoop cluster. Prior to Hadoop 2.X this programming algorithm was integrated into the Resource Manager and was collectively referred to as MRv1 (MapReduce version 1). Starting with Hadoop 2.X, the algorithm part and the resource management part were separated into MapReduce and YARN respectively, these are collectively referred to as MRv2 (MapReduce version 2)
Apache Kafka

Apache Kafka is a distributed streaming platform which is used for building real-time data pipelines and streaming apps. The Architectural diagram above shows the main modules of Apache Kafka, a brief description follows
Kafka Brokers
This is the component that the consumers and producers communicate via API to send and receive messages. You typically will have multiple Kafka brokers for high-availability within a cluster.
Zookeeper
In a Kafka cluster, Zookeeper is needed among other things for service discovery and leadership election of Kafka brokers. It’s basically the central repository used by various distributed components of Kafka to communicate with each other and share metadata information related to Kafka cluster through it.
Producers
Kafka Producers use Kafka Producer API to send messages to topics.
Consumers
Kafka Consumers use Kafka Consumer API to receive messages from topics. In this article Apache Spark is one such Consumer.
Topic
Topics are named set of records (messages). Kafka stores Topics in logs. A Topic log is broken down into multiple partitions. Each Topic partition is replicated across Kafka brokers to provide data redundancy in case one Kafka broker fails. Topics provide a de-coupled publisher-subscriber style messaging model for sharing data.
Apache Spark
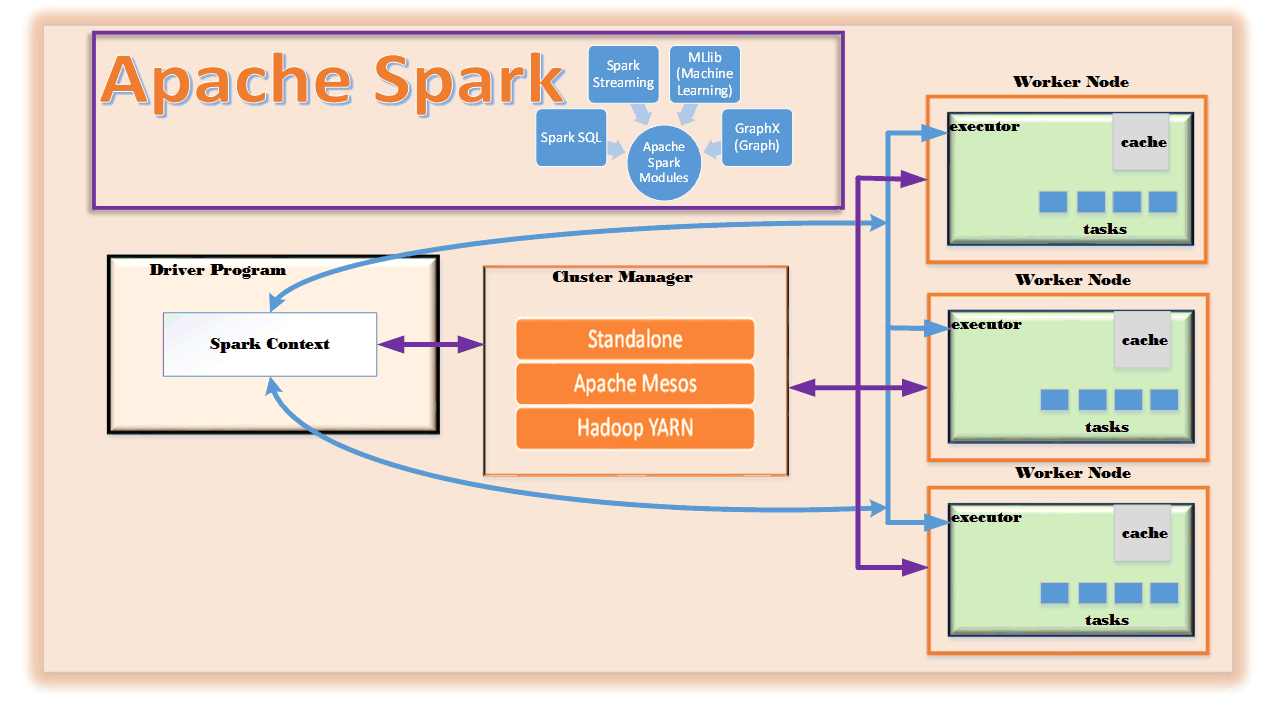
Apache Spark provides an engine to do large scale data processing. It provides multiple modules each meant for a different data processing purposes, a brief description of the modules follow
Spark SQL
This module allows you to run SQL type queries on data that is not typically stored in a RDBMS. SQL is a well-accepted scripting language to perform data analysis and Spark SQL is trying to minimize the learning curve of data scientist by providing a familiar scripting language to them; the alternative will be to write the same via Map functions and Reduce functions. By the way, Spark SQL behind the scene uses Map and Reduce functions also, it’s just abstracting those details from user’s who are writing Spark SQL.
Spark Streaming
This module allows real-time data analysis of stream data. It provides libraries and API to stream data from Apache Kafka, Amazon Kinesis, direct TCP ports and many other streaming sources. In the “Use Case” section of this article, when I mention Spark I really mean, using Spark streaming module.
MLlib
This is the Machine Learning module of Apache Spark and in the Use Case” section I mention where this module can be used in real-world application.
GraphX
This is the graph computational engine of Spark that allows users to build and transform graph structured data at scale using Spark GraphX API.
The Architectural diagram above shows the main components of Apache Spark ecosystem, a brief description follows
Driver Program (Spark Context)
This is the client program that interacts with Spark API; Scala is the native functional programming language platform for Apache Spark. Apache Spark does provide similar API interfaces in Java and Python. The Driver program is what sets up the Spark Context that is used to interact with the Apache Spark cluster.
Cluster Manager
This is the component of Apache Spark that manages interaction with the Worker Nodes to distribute the Spark jobs to those Worker nodes for execution. Apache Spark supports following three types of cluster manager configuration (NOTE: there is an experimental support for Kubernetes (K8S))
- Standalone – this runs the cluster manager as a part of Apache Spark cluster
- YARN – this uses Hadoop 2 resource manager (YARN) for cluster management
- Apache Mesos – this is a more generic resource manager similar to YARN but is not restricted to managing clusters in Hadoop only.
Worker Node
Worker nodes are the ones responsible for providing system resource details to the Cluster Manager so it can schedule jobs at the appropriate Worker nodes for job execution based on resource availability at that Worker node. Each application gets an “executor” to run on each Worker node and the executor is the one that runs multiple tasks for the application and is also responsible for providing in-memory caching for faster processing. The Spark Context started by the Driver Program communicates directly with the executors in parallel on each Worker node for job execution status. The Driver Program also splits the job into tasks that needs to be executed in parallel on each Worker node by the executor.
Use Case
Now that you have a quick overview of the technologies involved. Let’s consider where these can be used together to do data analytics and also do predictive analytics. The figure below shows one such use case.
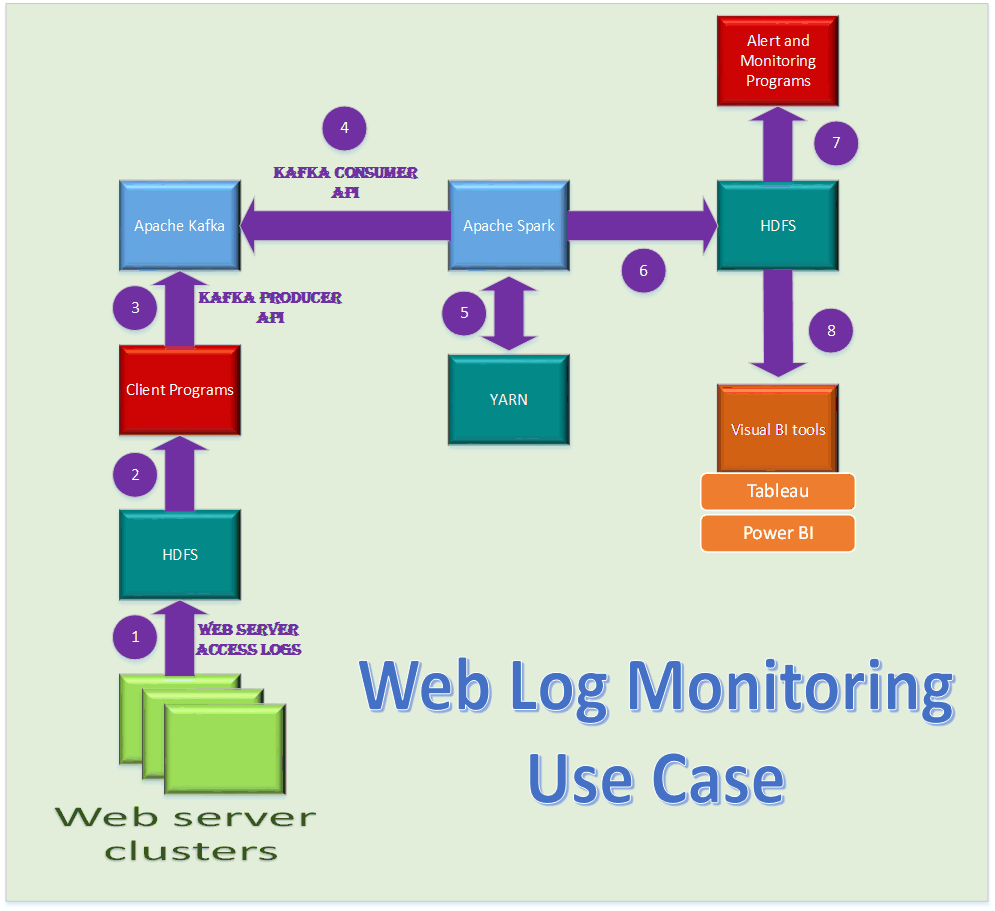
A few observations about the above use case
- Point 1: is the entry point to transfer web server access/error logs to Hadoop’s HDFS.
- Point 2: is where the client programs read data from HDFS and submits the same to Apache Kafka for streaming.
- Point 3: is where the client program uses the Producer API of Apache Kafka to send “messages” to Topic for consumption.
- Point 4: is where Kafka consumers (Apache Spark in this example) uses the Consumer API of Apache Kafka to consume messages from the Topic - messages contain web log entries that need to be analyzed by Apache Spark
- Point 5: Apache Spark can analyse the data in real-time by submitting Spark jobs in Hadoop cluster using Hadoop’s resource manager YARN.
- Point 6: Apache Spark can then save the results in Hadoop’s HDFS file system for further actions
- Point 7: You can have Alert and Monitoring programs that can take actions based on Apache Sparks’ real-time data analytical results. A few of the possible actions these programs can do is listed below
- The results can store which IP addresses are generating more web traffic with “error” results. The programs can use the “per IP” count of “errors” as a metrics to determine which IP’s can be black listed as they could be potential hackers doing web scan to exploit website vulnerabilities
- The result can store top 10 web pages visited by user community and accordingly re-align the website navigation to encourage users to stay longer on their website thereby by increasing the likelihood of them purchasing more items from your website
- Using the MLlib module of Apache Spark you can do machine learning through algorithms to generate results that can predict what items a user is most likely to buy based on web pages the user visits on your site, you can accordingly change the home page for that user the next time he visits you website (predictive analytics is the point I am trying to get across here).
- Point 8: Visual BI tools like Tableau and Power BI have connectors that allow you to connect directly to Hadoop. You can perform visual data analysis based on the results stored by Apache Spark in HDFS and look for patterns from which you can learn and adapt.
As you can see, the Use Case can be extrapolated to be used for many real-world applications and the possibilities are limitless (I hope you are getting excited to use this concept at your work place).
A few takeaways
- It’s possible to use Kafka and Spark alone and not use Hadoop. Hadoop is only needed if you have big data to handle (petabytes not terabytes of data)
- I am using Kafka for streaming but if you want you can use other streaming technologies like – Apache Storm, Amazon Kinesis.
- If you do not have a need to do real-time Data analytics then you do not need to use Apache Kafka. You can just use Apache Spark’s other libraries like Spark SQL, MLLib to do data analysis and perform predictive analytics
- It’s possible to use the output of Apache Spark’s analysis as data feed for Visual Analytical tools like – Microsoft Power BI and Tableau.
- Visual Analytical tools like Power BI and Tableau will be something that you will end up using in your data analysis as they provide pretty fancy Dashboards and Visual Graphs that help you and the management executives visually understand the data trends quickly
- Try to use equivalent technologies provided by Cloud providers, instead of building the clusters from ground up through bare metal servers or Virtual Machines. The only down side to this is you cannot control upgrades of the various versions of these technologies at a pace you want as a result you will be restricted to using older versions of these technologies while the Cloud providers give you an easy upgrade path. As an example of using Cloud technologies equivalent the following combination is a good alternative to Apache Kafka, Apache Spark and Apache Hadoop if Amazon AWS is your cloud provider –
Amazon Kinesis and Amazon EMR cluster with Spark libraries enabled.
Use this approach if you are using AWS instead of building your own clusters for Hadoop, Kafka and Spark via the EC2 bare-metal server’s route.
NOTE: As mentioned before flip side of using Cloud providers equivalent technologies is getting married to the technology versions provided by the Cloud provider. So pick your poison is what I am saying. The benefit is infrastructure management work is simplified and standing up clusters is just a few clicks via the AWS management console (all right not trying to be a sales person here for Amazon, you will still need a DevOps team)
Conclusion
I hope this article will inspire you to do data analytics with your real world use cases. Please refer to the following blog - http://pmtechfusion.blogspot.com/2017/11/big-datadata-science-analytics-apache.html if you are interested in reading detail installation steps for the above technologies and do some hands-on. I have also provided a python script for the “Use Case” described in this blog and explained how to execute the same.