Introduction
In this article I will provide an overview of how you can send logging information from Kubernetes (K8s) cluster to a central place for data analysis. Even though I am providing explanation for a K8s cluster the same approach applies for non-containerized applications.
Architectural Overview
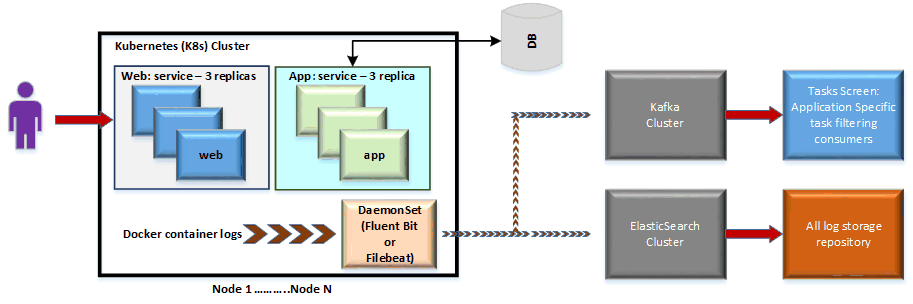
A typical log data generation flow is described below
- User will access different applications that are hosted on K8s cluster. In the above example I am showing two K8s services each with three replica sets. The K8s cluster provides load-balancing and all the capabilities needed for High Availability (HA) and auto-scaling. These user interactions will create application specific logs, for example: an invalid login attempt, runtime application exception etc.
- The K8s Cluster can be a 3(or N) Node cluster for small scale applications. On each of the nodes you can run K8s DaemonSet that will stream log data from Docker containers hosted on that Node to Kafka cluster or ElasticSearch (ELK – ElasticSearch, Logstash and Kibana) Cluster.
- The DaemonSet will run light weight version of Fluent (Fluent Bit), it’s possible to use Filebeat instead of Fluent Bit if you want to stay within the ELK ecosystem.
- I am using Kafka cluster to provide application specific filtering and routing.
- The ELK cluster is used to store all logs and acts as a central repository for log storage.
Component description:
Kubernetes (K8s) Cluster
This is the typical Kubernetes cluster that will host containerized applications.
Web: service – 3 replicas/App: service – 3 replicas
This represents a typical distributed application where your web application is hosted as a Service within K8s cluster and your application layer is also hosted in the same cluster.DB
I have shown the DB component outside the K8s cluster as that helps having specialized teams optimize that layer outside of K8s. Also when I say DB, it’s not necessarily relational DB, it can be a NoSQL database like MongoDB or a combination of both. Also it’s not a hard and fast rule to have data layer outside the K8s cluster, I am just providing what is a typically preferred approach.
DaemonSet (Fluent Bit or Filebeat)
Either a Fluent Bit container or a Filebeat container can be deployed as a DaemonSet on each K8s cluster node, the container can be configured to stream log information from Docker location (“/var/lib/docker/containers”).
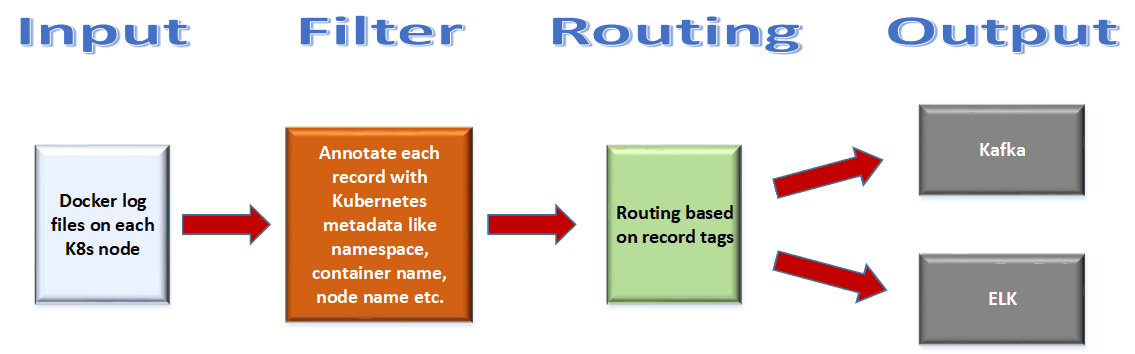
NOTE: You can also use the same container to stream logs from other locations like “syslog”.Assuming you are using Fluent Bit, within the K8s cluster you will have to define ConfigMap that will be referenced by the DaemonSet Fluent Bit container that will then use the mounted configuration files and stream log contents to either ELK or Kafka depending on how the Fluent Bit configuration file is defined. Below is a high level overview of how the Fluent Bit configuration setting is defined
- You start by defining a starting configuration file which will load different sections of Fluent Bit configuration by referencing other files (via includes)
- You will have one file defining the different inputs – which in this case will be the location of Docker file container logs on each node, you will use the standard “tail” plugin that comes with Fluent Bit for streaming log contents.
- You will have one file defining the different filters – in this case you will use the standard “kubernetes” filter that comes with Fluent Bit to annotate each record with details that include information like – pods namespaces, node name, container name etc. This additional metadata can be used later on to do data analytics via Kibana in the ELK cluster.
- You will have one file for different outputs – in this case you will define one output stream for Kafka using the standard “kafka” output plugin and another for ElasticSearch using the standard “es” plugin
Node 1 ………..Node N
This component represents the actual nodes that are hosting the K8s cluster. For smaller applications start with a 3-node cluster and then scale from there.Kafka Cluster
The Kafka cluster is used to filter log records that are getting streamed to it in order for you to create application specific Tasks (through the Kafka Consumers) or send alert notifications, SMS etc.
ElasticSearch Cluster
The ElasticSearch cluster is used to store all log records so you can use Kibana to create visual dashboards and use the ELK console client to perform data analysis.
A few implementation details to consider
- Even though I have mentioned Fluent Bit as the log forwarder in this article, you can certainly use Filebeat as a viable alternative if you want to stay within the ELK ecosystem.
- You should consider defining buffer limits on your Fluent Bit input plugin to avoid back pressure
- By default Fluent Bit does an in memory buffering of records while data is routed to different outputs, consider using file system buffering option provided by Fluent Bit to avoid data loss due to system failure.
- I have used “Kafka” as a central filtering option for log records. It’s possible to use filters at the Fluent Bit level to remove records before they make their way to the Kafka topic. I prefer the former as that way I have all the log records in the Kafka Topic, in case if I need to do detailed analysis later. It also eliminates the need to utilize CPU/RAM processing power at the container level if the filtering of log records is not done there. The benefit of doing filtering at the Fluent Bit level is that less data transmits over the network(it’s a trade-off)
Conclusion
I hope you liked this article.