Introduction
In this article I will provide an overview of following technology stack
- Single Sign On (SSO) identity/access management using Shobboleth IdP, CAS server and Shobboleth Service Provider (SP)
- Using Spring Boot for Rapid Application Development
- Redis to cache Spring data as well as its use as a second level cache for ORM (Hibernate/JPA)
- I will also provide an overview of JHipster – a Swiss army knife for code generation
There is a lot to cover from the above technology stack, the intent of this article is to provide pointers to create enterprise grade scalable system and assist Software Architects in taking decisions that will help in scaling their systems using the mentioned technology stack. I know this is heavily tilted towards Java audience but a similar approach can be used for .NET using ER framework.
Architectural Overview
The above logical diagram represents a high level overview of the technology stack involved.
A typical user activity flow is described below
- User will start the flow by accessing the protected resource (web application) via the browser
- The Service Provider (SP) will intercept that request and will redirect the user to the identity Provider (IdP)
- After successful authentication and exchanging of SAML token the Service provider will redirect the user request to the web application and will set Authorization Headers that the web application can read and determine what the user is authorized to do. These authorization headers are not sent back to the user browser for security reasons. Typically you will have an Apache server hosting your Service provider acting as a reverse proxy for your web application which is hosted on Tomcat.
- Depending on what the user is authorized to do different User interface functions will be enabled for subsequent actions.
In this flow, I am assuming the authorization piece (roles, access policies etc.) is application dependent and in the above diagram is stored in RDBMS (MySQL) database. It’s recommended to externalize this part for all applications into a Central Access Management System (similar to Identity Authentication - IdP) thereby standardizing access management across all applications.
Component description:
LDAP server
In the overall Single Sign On (SSO) flow, you want to ensure your user passwords are centrally managed. LDAP server represents one such option
Identity Provider (IdP) – like Shibboleth IdP or CAS Server
In the SSO flow, this component will abstract the authentication piece from multiple applications and will provide a standard interface for authentication to multiple applications. You can either use Shibboleth IdP which uses SAML protocol for authentication or CAS server if you are using the CAS protocol. (NOTE: CAS server also supports SAML).
Service Provider (SP) – like Shibboleth Service Provider
In a SSO flow you can protect your web application behind a Service Provider which can co-ordinate the SAML SSO flow with your IdP and pass the authentication details via HTTP headers to your application. Shibboleth SP can be used as a service provider to perform such a function. If you happen to use the Docker image for this component then it will be running Apache server and can be configured to act as a reverse proxy for your Web application. Alternatively you can co-locate the SP with your web application. If you are using Spring then you can use Spring Security SAML that provides SAML support within your application and can act as a Service Provider for your Identity Provider. I still prefer a separate Service Provider configuration via Apache reverse proxy approach as that is abstracting the cross cutting responsibility from individual applications and also provides an extra layer of security through proxy function.
Web application
This is the protected resource (the web application) that the users are accessing in the SSO flow. In the following section I will provide further details on this component.
Redis Cluster (or AWS Elasticache or Azure Redis cache)
You can use Redis as a distributed Data Grid to reduce read load on your relational database. The Redis cluster can be build using virtual machines in your local data center or you can use cloud providers like AWS/Azure that provide Redis cluster as a service. You can use client drivers (like Redisson) that can then communicate with your Redis cluster. Redisson also provides capabilities to integrate with Hibernate to provide second-level caching via Redis to JPA queries thereby reducing database queries and speeding up performance of your application. Redisson comes in two flavors – professional edition and open source edition. I recommend going with professional edition as that gives you features like local caching, data partitioning, XA transaction to name a few. These features will come in handy to provide enterprise level scalability (and the cost is not that bad)
RDBMS (like MySQL)
In the diagram this component is where your data storage will occur. If you are using MySQL you can create read replicas on top of your Redis Cluster to further improve read performance. You can also use a NoSQL database like MongoDB instead of a RDBMS like MySQL to store data.
A few implementation details for the components to consider
There are Docker images available in Docker Hub for
- Shibboleth IdP
- Shibboleth SP
- CAS Server
- Tomcat
- OpenLDAP (if you want to use this as your LDAP server)
- Redis
- MySQL
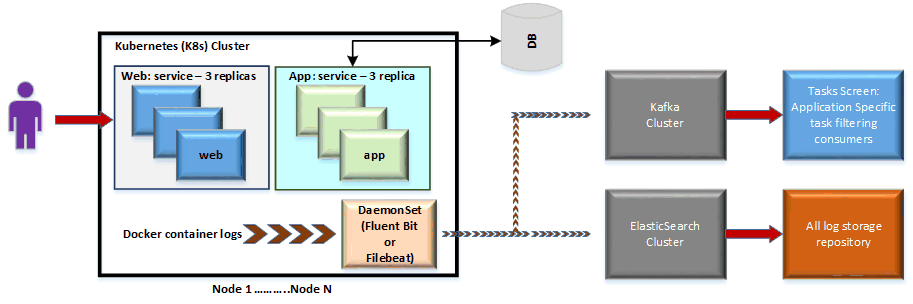
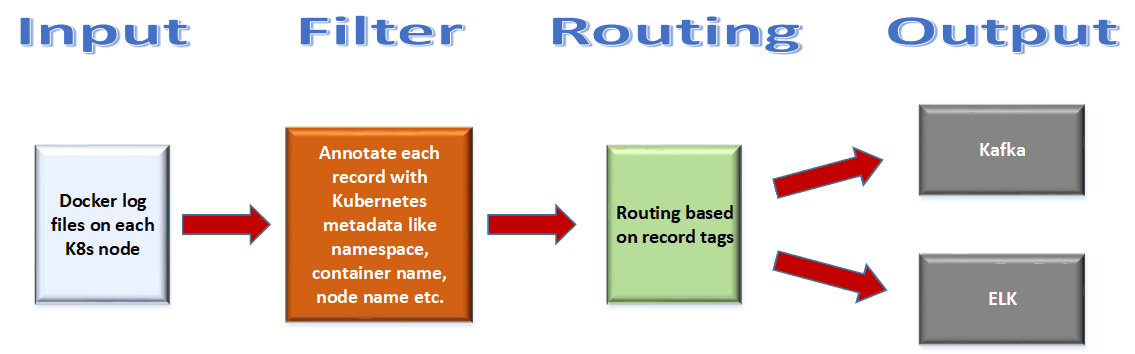
You can use these images to containerize your application and deploy it in container aware environments like Kubernetes (K8s), EKS, AKS, GKS or ECS. Containerizing your components will help you design and build a scalable, highly available and resilient system.
Web Application Architecture:
The above diagram provides further decomposition of the web application component.
Spring MVC/Spring Boot
On the left hand side of the dotted line, you will see decomposition of a typical Spring MVC framework. The right hand side shows the same using Spring Boot. If you are heading towards Micro service style architecture and wish to use Java platform then using Spring Boot is the way to go. It allows you to build applications rapidly. If you are building even monolithic applications I suggest you start with Spring Boot since it utilizes under the hood the same concept that Spring MVC does – Dependency Injection (DI) and Inversion of Control (IoC). It also reduces a lot of boiler-plate code which encourages rapid application development. In my opinion, in the Java world Spring Boot is the answer to other competing technologies like NodeJS, Ruby on Rails and/or Django framework (python) in order to do rapid application development.
For the rest of the topics in this article I am going to assume the use of Spring Boot
Redis Cluster (or AWS Elasticache or Azure Redis cache)
This component is used to provide caching at two levels
- At the application level (Spring) and
- As a second level cache for Hibernate
NOTE: Hibernate provides first level caching at the session level by default.
As mentioned before if you are using Redisson client (open source or professional), it supports connecting to local data center Redis cluster as well as AWS/Azure hosted Redis clusters.
View
You have multiple options to pick from
- If you are looking for server side rendering of user interface (UI) then you can pick either JSP or Thymeleaf or any other templating engine.
- If you are building a Single Page Application (SPA) you can select Angular, React or Vue (there are many more choices to pick from in the SPA world but these three cover 80%+ of the SPA market interest)
In the next section I am going to talk about a code generation tool called JHipster that will allow you to build production grade code very quickly.
JHipster:
The above diagram provides a high level overview of how you can integrated SSO with SPA application. I thought of including this section so I can talk about one of my favorite code generation tool – JHipster. I call it a Swiss army knife for code generation. In the above diagram the dotted line section is generated automatically for you by JHipster.
The user interaction flow described earlier is still valid which is the user starts the flow by trying to access the protected resource (the SPA application in this case), the only delta here is as follows:
Once the service provider redirects the user internally (via reverse proxy) to the location where the SPA application is hosted. The rest of the interaction from that point forward in terms of authorization between the SPA application and the server side component (which typically is REST API exposed via Spring Boot) is done by exchanging JSON Web Tokens (JWT).
In order to code generate with JHipster, you typically start with creating an Entity or Domain model using JHipster online graphical editor. You can then save the model to a file which contains the textual representation of the graphical model in what’s called JHiphster Domain Language (JDL). You can feed that JDL file to JHipster’s code generation engine and voila you have a working application with basic CRUD operations ready for all your Domain entities. JHipster has a lot of options to generate code for different technology stacks but at a high level you get to decide if you want to create
- A Monolithic application or a
- Micro Service application
When you select a monolithic application, JHipster will auto generate code spread across following layers using technology stack that you select during initialization step. Some of the layer choices are mentioned below
- It creates a SPA application using either Angular or React at the client side.
- On the server side it creates a Spring Boot REST API driven server layer
- It also through Hibernate/JPA layer give you option to talk with RDBMS layer (MySQL, Oracle, SQL Server etc.)
- It allows you to pick caching option for Hibernate and Spring Boot. Unfortunately not Redis at the time of writing this article. However, given that Spring Boot and Hibernate provide annotation based caching capability that is independent of which Cache provider you are using. The amount of time to change the code to use Redis is very much restricted to touching one or two files at the maximum. The rest of the Spring Boot/Hibernate code is unaware of the underlying caching provider. With that said JHipster does generate code automatically for Ehcache, Hazelcast, Infinispan and Memcached. With JCache API I have a feeling that JHipster code generation will cover most of the other caching providers including Redis in near future.
- It integrates the client side calls with the server side call using JWT token authentication flow built into the Spring Security. If you want to authenticate users using the Identity provider approach mentioned earlier. All you have to do is use the Pre-authentication flow that Spring Security provides out of the box thereby delegating the authentication piece to your IdP and then you can use JWT tokens for subsequent authorization. NOTE: It is also possible to use OpenID Connect for SSO with Single Page application as an alternative to IdP.
A few things at the time of writing that you should be aware of in terms of Jhipsters cons
- JHipster does not auto generate code for versioning or Optimistic locking for hibernate entities
- JHipster requires JDK 1.8 for code generation. However, you can run the code generated by JHipster on Java 11 but you will receive warnings that some of the class libraries (especially Hibernate) are using native calls which is discouraged. Anyhow I do not think this is necessarily going to be a big issue once JHipster catches up with using the right version of Hibernate in its next release that does not use these java native calls. Just so you know your code will still work with Java 11, you will get some nasty warning’s in your application server logs that for the time being you can ignore.
- Given the choice of technology stack and more specifically the component versions within the individual technology that JHipster uses to generate code, one thing you need to be aware of is being locked down with specific version of that technology. For example, if JHipster code generation is using the most recent version of Angular today, six months down the road that version may become obsolete and you will have to do the upgrade manually or wait for JHipster to do catch-up.
- It only generates code for CRUD operations and does not generate code for business specific workflows which you still need to design and code using your developers but in my opinion it generates a very good code base for you to build from
Conclusion
I hope you liked this article. I plan to write an article on Event Driven architecture as well as Microservices when to use them and most importantly when not to use them next. As always send me constructive feedbacks.