Introduction
In this article I will provide details of how to use the ELK+ stack for doing
- Full Text searching (using google type search capability)
- Visual Data Analysis of log data generated from various sources (like server syslog, apache logs, IIS logs etc.)
Architectural Overview

Filebeat
In the ELK+ stack, Filebeat provides a lightweight alternative to send log data to either the Elasticsearch directly or to Logstash for further transformation of data before its send to Elasticsearch for storage. Filebeat provides many out of the box modules to process data and these modules can be configured with minimal configuration to start shipping logs to Elasticsearch and/or Logstash.
Logstash
Logstash is the log analysis platform for ELK+ stack. It can do what Filebeat does and more. It has inbuilt filters and scripting capabilities to perform analysis and transformation of data from various log sources (Filebeat being one such source) before sending information to Elasticsearch for storage. The question comes when to use Logstash versus Fliebeat. Typically you can consider Logstash as the “big daddy” for Filebeat. Logstash requires Java JVM and is a heavy weight alternative to Filebeat which requires minimal configuration in order to collect log data from client nodes. Filebeat can be used as a light weight log shipper and one of the source of data coming over to Logstash which can then act as an aggregator and perform further analysis and transformation on the data before its stored in Elasticsearch as shown below

Elasticsearch
Elasticsearch is the NoSQL data store for storing documents. The “term” document in Elasticsearch nomenclature means “json”- type data. Since the data is stored in “json” format, it allows a schema less layout thereby deviating from the traditional RDBMS-type of schema layouts and allowing flexibility for the json-elements to be changed with no impact on existing data. This benefit comes due to the Schema less nature of Elasticsearch data store and is not unique to Elasticsearch. DynamoDB, MongoDB, DocumentDB and many other NoSQL data stores provide similar capabilities. Elasticsearch under the hood uses Apache Lucene as the search engine for searching documents it stores in its data store.
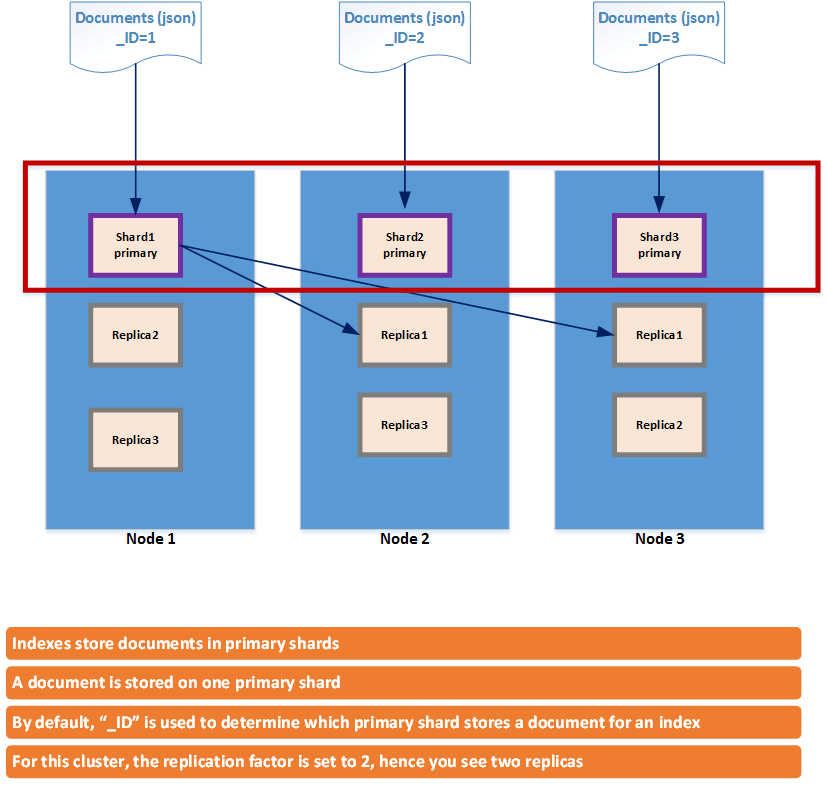
Data (more specifically documents) in Elasticsearch are stored in indexes which are stored in multiple shards. A document belongs to one index and one primary shard within that index. Shards allow parallel data processing for the same index. You can replicate shards across multiple replicas to provide fail-over and high availability. The diagram below shows how data is logically distributed across an Elasticsearch cluster comprising of three nodes. A node is a physical server or a virtual machine (VM)
Kibana
Within the ELK+ stack, the most exciting piece of the stack is the Visual Analytical tool – Kibana. Kibana allows you to do visual data analysis on data that’s stored in Elasticsearch. It allows you to visualize data by providing many visualization types as shown below

Once you create visualizations using the above visualization types. You can create a Dashboard that can includes these visualizations on a single page to provide visual representation of data stored in Elasticsearch from different viewpoints, a technique used in Visual data analysis to identify patterns and trends within your data.
Use Cases for ELK+ stack:
Use Case 1
In this use case we can use Elasticsearch to store documents to create a google type search engine within your organization. Documents referred to in this use case are Word documents, PDF documents, image documents etc. and not the json-type documents stored in Elasticsearch.

The above diagram shows two user driven workflows in which Elasticsearch cluster is used by web applications.
Workflow1
Users upload the files using the Web application user interface. The web application in turn behind the scene uses the Elasticsearch API to send the files to Ingest node of Elasticsearch cluster. The web application can be written in Java (JEE), Python (Django), Ruby on Rails, PHP etc. Depending on the choice of programming language and application framework, you can pick the appropriate API l to interact with the Elasticsearch cluster.
Workflow 2
Users use the web application user interface to search for documents (like PDF, XLS, DOC etc.) that are ingested into the Elasticsearch cluster (via “workflow 1”).
Elasticsearch provides “Ingest Attachment” plugin to ingest documents into the cluster. The “Ingest Attachment” plugin is based on open source Apache Tika project. Apache Tika is an open source toolkit that detects and extracts metadata and text from many different file types (like PDF, DOC, XLS, PPT etc.). The “Ingest Attachment” plugin uses the Apache Tika library to extract data for different file types and then store the clear text contents in Elasticsearch as json-type documents. The plugin also stores the full-text extract version of the different file types as an element within the json-type document. Once the metadata and the full-text extraction is done and stored in clear-text json-style format within Elasticsearch. From that point forward Elasticsearch uses the Apache Lucene search engine to allow full-text searching capability by doing “Analysis” and “Relevance” ranking on the full-text field.
Use Case 2
Using Elasticsearch as a NoSQL data store to store logs from various sources (apache server logs, syslogs, IIS logs etc.) to do visual data analysis using Kibana. The architectural diagram in section titled “Architectural Overview” in this article shows how ELK+ stack can be used for this use case. I am not going to elaborate more on this use case besides providing a few additional informational points (or take away notes)
- It’s possible to directly send log data from Filebeat to Elasticsearch cluster (bypassing the Logstash)
- Filebeat has a built in backpressure sensitive protocol to slow down the sending of log data to Logstash and/or Elasticsearch if they are busy doing other activities.
A few take away
- In order to avoid the Elasticsearch nodes from doing extraction of metadata and full text data from different file types while files are sent to “Ingest Attachment” plugin in real time and there by resulting in CPU and resource load on the ingest node. An alternate way to do the same will be to use Apache Tika as an offline utility and use it to extract metadata and full-text data using a batch program and then using that batch program to send data directly to Elasticsearch as a “json-type” document. This eliminates increasing payload pressure on Elasticsearch cluster as the batch program can be run outside the cluster nodes, full-text data extraction is a very CPU intensive operation. This batch program approach will also work for Apache Solr as the same batch program can be used to route the data to Apache Solr and/or Elasticsearch
- Another benefit of off-loading the full-text data extract operation outside of Elasticsearch is that you do not have to use Apache Tika for metadata and full-text data extraction, you can use other commercial alternatives.
- For High availability and large Elasticsearch clusters, try to utilize different Elasticsearch nodes-types (a node is a physical machine and/or VM in an Elasticsearch cluster). Below are the different Elasticsearch note-types
This node-type allows the node to be eligible for being designated as a master node within the Elasticsearch cluster. For large clusters, do not flag “master eligible” nodes to function as “data” nodes and vice-versa
Data Node
This node-type allows the node to be a “data” node in an Elasticsearch cluster.
Ingest Node
This node-type allows the node to be a “ingest” node. If you were using the “Ingest Attachment” plugin, then it is a good idea to send data traffic associated with file uploads to “ingest” only nodes as the full-text extraction from different file-types is a very CPU exhaustive process and you are better off dedicating nodes just to perform that operation
Coordinating Node
This node-type allows the node to co-ordinate the search request across “data” nodes and aggregate the results before sending the data back to the client. As a result, this node should have enough memory and CPU resources to perform that role efficiently.
Tribe Node
It’s a special type of “coordinating” node that allows cross-cluster searching operations
NOTE: by default an Elasticsearch node is “master-eligible” node, “data” node, “ingest” node as well as “coordinating” node. This works for small clusters but for large clusters you need to plan these node roles (types) for scalability and performance.
- Both Apache Solr and Elasticsearch are competing open source platforms utilizing Apache Lucene as the search engine under the hood. Elasticsearch is more recent and is able to benefit from lessons learned from previous competing platforms. Elasticsearch has gained popularity due to its simplicity of setting up the cluster versus Apache Solr and as mentioned earlier many cloud providers (like AWS) are providing Elasticsearch as a “Platform” as a service (PaaS)
- Elasticsearch has a product called X-Pack, at this point of time you have to pay for this but this year the company behind Elasticsearch is going to make the X-Pack offering open source. X-Pack provides following capabilities
- Secures your Elasticsearch cluster through authentication/authorization
- Sending alerts
- Monitoring your clusters
- Reporting capability
- Exploring relationship between your Elasticsearch data by utilizing “Graph” plotting.
- Machine Learning of your Elasticsearch data
Conclusion
ELK+ stack is an open source platform that allows you to quickly set up a cluster for performing visual data analysis as well as provide a “google” search like capability within your organization and it’s all “free”. I hope this article will give you enough details to use the ELK+ stack in your own organization
Thanks, Admin for sharing such a useful post, I hope it’s useful to many individuals for developing their skills to get a good career.
ReplyDeleteDocker Training in Hyderabad
Kubernetes Training in Hyderabad
Docker and Kubernetes Training
Docker and Kubernetes Online Training